



.png)
Fonte: Shutterstock.
Deseja ouvir este material?
Áudio disponível no material digital.
Praticar para aprender
Caro aluno, atualmente, vivemos na era da informação. A bioestatística pode ser pensada como a ciência da aprendizagem a partir de dados, já que possui ferramentas necessárias para conseguirmos entender toda informação disponível.
A impossibilidade de estudar uma população inteira faz com que tenhamos que trabalhar melhor com a capacidade de registro de dados e a sua compreensão. Por isso, contamos com a expansão do conhecimento científico, das áreas de pesquisa e dos instrumentos de investigação.
Os dias atuais nos mostram a necessidade de entender os fenômenos naturais e sociais, a otimização de recursos, o planejamento de atividades, a redução de riscos e a previsão de resultados para uma correta tomada de decisão, seja em uma empresa ou nas finanças da casa. Em todas as situações, a estatística pode ser utilizada, inclusive na educação física. Por exemplo, podemos utilizar com os alunos de uma escola as técnicas estatísticas, como média, mediana e moda, e realizar as apresentações gráficas de acordo com os dados.
Por isso, nesta seção, estudaremos sobre as medidas de tendência central, compreendendo os principais conceitos e verificando a correta utilização da média e da mediana, além da melhor forma de apresentação dos resultados na forma de gráficos.
No processo de aprendizagem da estatística descritiva dos dados, podemos encontrar facilmente as definições e as formas de utilização em diversos sites de buscas. Contudo, a inferência e a interpretação dos dados são variáveis mais complexas e de suma importância nesse processo, pois precisamos entender o contexto em que as pessoas participantes estão inseridas, para conseguirmos realizar a generalização da maneira correta.
Sabendo que o profissional de educação física possui o conhecimento para atuar no campo da saúde e nas unidades de saúde do Núcleo Ampliado de Saúde da Família (NASF), ele pode promover a atividade física e, em sua empreitada, se deparar com um grupo de 13 alunos que realizam atividades em suas casas e possuem algumas características, de acordo com seu levantamento a seguir.
Você deverá apresentar esses números em uma reunião, desta forma, a proposta é construir um gráfico de colunas baseado nos dados da Tabela 4.3.
Tabela 4.3 | Dados para serem utilizados na resolução do problema
Fonte: elaborada pelo autor.
| Lorem ipsum | Lorem ipsum | Column 3 | Column 4 | |||
|---|---|---|---|---|---|---|
| Registro | Sexo | Estado civil | Escolaridade | Tabagismo | Diabetes | IMC |
| 1 | Masculino | Casado | Fundamental incompleto | Ex-tabagista | Sim | 23 |
| 2 | Feminino | Solteiro | Fundamental incompleto | Nunca fumou | Sim | 32,1 |
| 3 | Masculino | Amigado | Sem estudo formal | Ex-tabagista | Não | 26,2 |
| 4 | Feminino | Viúvo | Fundamental incompleto | Ex-tabagista | Sim | 30,8 |
| 5 | Feminino | Casado | Fundamental completo | - | Sim | 27,1 |
| 6 | Feminino | Casado | Médio completo | Nunca fumou | Sim | 28,4 |
| 7 | Masculino | Casado | Superior completo | Nunca fumou | Não | 27,1 |
| 8 | Feminino | Casado | Fundamental incompleto | Tabagista atual | Não | 30,3 |
| 9 | Masculino | Casado | Fundamental incompleto | - | Não | 30,8 |
| 10 | Masculino | Casado | Médio completo | Nunca fumou | Sim | 28,7 |
| 11 | Feminino | Viúvo | Médio completo | Nunca fumou | Não | 22,9 |
| 12 | Masculino | Casado | Médio completo | Nunca fumou | Não | 30,8 |
| 13 | Masculino | Solteiro | Fundamental incompleto | tabagista | Não | 37,4 |
Bons estudos!
conceito-chave
Estatística descritiva
A estatística descritiva se refere aos números que resumem e descrevem um conjunto de dados. Ela apenas apresenta os dados e não representa uma generalização da amostra geral. A técnica usada para generalizar as conclusões obtidas com uma amostra de determinada população é a inferência estatística.
Extrair grande quantidade de informações demanda técnicas específicas, tanto para coleta, organização e síntese dos dados quanto para a análise que será realizada. Com essa grande quantidade de dados, a apresentação deles (em seu formato bruto) não permite que possam ser extraídas informações consistentes. Por outro lado, ao organizá-los previamente, possibilitamos a síntese e a simplificação.
O processo da análise dos dados é chamado de análise descritiva ou análise exploratória dos dados, e consiste em responder às perguntas feitas inicialmente no planejamento da elaboração do estudo. Esse processo começa a partir da escolha do instrumento a ser utilizado para coleta dos dados, passando pela etapa em que se busca transformar os dados coletados em possíveis respostas quantificadas e que possam caracterizar a amostra do estudo.
Suponha que realizaremos um estudo sobre o perfil e o nível de atividade física de uma população. Provavelmente, as informações que devemos considerar são: sexo, idade, tempo dispendido em atividade física por semana e quantidade de dias de prática de atividade física. Alguns dados podem ser coletados na forma bruta ou em categoria, como a idade.
As vantagens dessa forma de coleta é a possibilidade de se ter uma visão geral dos dados, proporcionar maior flexibilidades de análise e criar outros tipos de variáveis (assunto abordado na unidade anterior). Importante entendermos que os conjuntos de dados possuem nomenclaturas específicas, sendo divididos em elemento, variável, observação e caso.
- Elemento: é cada uma das unidades no estudo que são observadas. Um conjunto de dados é formado por informações sobre a variável de interesse de cada elemento. Basicamente, é o indivíduo que está sendo avaliado, por exemplo, a pré e a pós-avaliação de determinada intervenção em um estudo com humanos.
- Variável: é a caraterística de interesse e que se pode medir, podendo apresentar valores diferentes, dependendo do elemento. Por exemplo, o sexo varia de acordo com cada elemento.
- Observação: é a informação que a variável apresenta para cada um dos elementos especificamente.
- Caso: é o conjunto de observações de um elemento determinado.
A análise exploratória é realizada através da primeira manipulação dos dados. Essa primeira etapa demanda tempo e uma grande quantidade de trabalho, pois se trata de uma tarefa manual, a qual requer cuidado para que não haja perda de dados e, posteriormente, possa haver o cruzamento das variáveis.
O primeiro passo para essa construção é a separação de cada variável de acordo com o perfil. Por exemplo, variáveis sociodemográficas (idade, sexo, escolaridade), hábitos de vida (tabagismo, dieta, prática de atividade física) e doença pré-existente (hipertensão, diabetes, câncer). A separação da variável por perfil é chamada de análise univariada (Tabela 4.3).
Em seguida, na tabulação das variáveis, as contagens das observações são resumidas em cada uma das variáveis, assim, podemos encontrar a frequência (que será dividida em absoluta e percentual).
Frequência absoluta consiste na quantidade de observações encontradas em uma dada categoria ou variável. A soma das frequências absolutas é igual ao número total de observações da variável (representado pela letra n). Já frequência percentual simples indica o percentual de cada variável que pertence à categoria. Ambas são apresentadas com exemplos na Tabela 4.4.
Tabela 4.4 | Exemplo da utilização das frequências absoluta e percentual
Fonte: elaborada pelo autor.
| Lorem ipsum | Lorem ipsum | Column 3 | Column 4 |
|---|---|---|---|
| Variável | N (%) | ||
| • 60 anos | 603 (58,2) | ||
| Masculino | 615 (59,4) | ||
| Escolaridade | |||
| Sem estudo formal | 135 (13,0) | ||
| Fundamental incompleto | 428 (41,3) | ||
| Fundamental completo ou Médio incompleto | 256 (24,7) | ||
| Médio completo ou Superior incompleto | 160 (15,4) | ||
| Superior completo ou Pós-graduação | 56 (5,4) | ||
| NA | 1 (0,1) | ||
| Branco | 681 (65,7) | ||
| Ex-tabagista | 383 (37,0) | ||
| IMC 25-30 | 398 (38,4) | ||
| Não-diabético | 612 (59,1) | ||
| Dislipidêmico | 489 (47,3) | ||
| Não-AVC | 827 (79,8) | ||
| Sedentário | 681 (65,7) |
Além das frequências, as variáveis podem ser analisadas em relação ao centro do conjunto dos dados, conhecido como medida de tendência central, a partir do qual identifica-se o valor representado em torno do qual os dados tendem a se agrupar com maior ou menor frequência. A forma mais usual de serem representados é por meio da média, mediana e moda. A moda é pouco utilizada, a não ser em casos em que queremos exatamente encontrar aquilo que é mais frequente. A média é certamente a forma mais comum, mas, em certos casos, a mediana é a melhor opção.
O cálculo da média se dá pela soma dos valores individuais, dividindo-os pelo número de participantes posteriormente. Ela () é representada pela fórmula:
A média pode ser vista como o centro do conjunto dos dados, mostrando o ponto de equilíbrio das observações. Imagine um conjunto de dados composto pela idade de cinco crianças (1, 1, 4, 8 e 10 anos), cuja média de idade é 4,8 anos. Agora, imagine a seguinte amostra e calcule a média dela: 2,0; 3,5; 4,5; 4,8; 6,5; 7; 7,5; 7,6; 7,6; 8,0. Perceba que ela não é representada por nenhum desses números, e que isso ocorre com valores aleatórios – como no exemplo da idade das crianças.
A média, porém, não dá mais informações sobre o comportamento do grupo de valores. Por exemplo, um aluno que obteve as notas 3, 4 e 5 em três provas possui média 4; outro aluno, com notas 0, 2 e 10, também tem a mesma média, mas o desempenho de ambos é nitidamente diferente. Nesse ponto, a média possui limitações para indicar o perfil da amostra, logo ela é bem empregada como medida de tendência central em grupo de dados com distribuição normal.
A mediana (md) é uma medida de tendência central de um conjunto de dados, na qual se divide o conjunto em duas partes com igual quantidade de observações. Considerando que esse conjunto de dados esteja ordenado, a mediana é o valor de observação que estará posicionado no centro, de forma que 50% das observações sejam valores abaixo da mediana, e os outros 50%, acima dela.
Exemplificando
Imagine nove estudantes e cada um com sua estatura (x1, x2, x3..., x9), todos colocados em fila de com acordo com seu tamanho, indo do menor para o maior. De acordo com os dados da figura a seguir, a média de altura é 1,26 m.
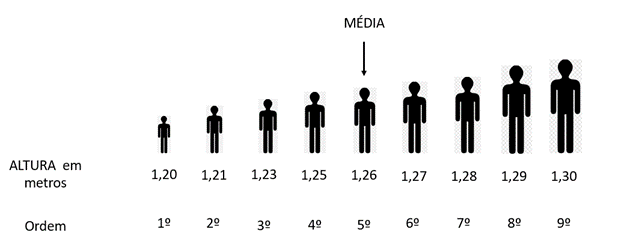
Considerando, agora, que o nono aluno possui 1,80 m, uma altura bem acima dos demais, a média desse conjunto seria de 1,31 m, valor esse acima do segundo mais alto, que é 1,29 m. A média, nesse caso, não poderia auxiliar na caracterização do perfil da amostra. Para representar a tendência central é utilizada a mediana, que fornece um valor que está no centro do conjunto de dados.
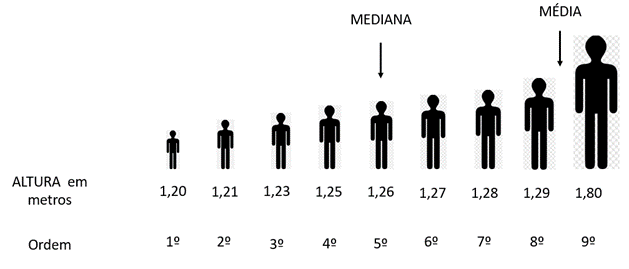
Segue o cálculo para a mediana com conjunto de dados ímpar:
A equação a seguir é utilizada para quando o número de observações é par, com isso a mediana será a média dos dois valores centrais.
Outra medida também é utilizada para dividir o conjunto de dados em um maior número de partes, sendo úteis para apresentação dos valores com uma distribuição assimétrica: percentil. A partir dela, divide-se o conjunto em cem partes de igual tamanho, e a mediana sempre será o percentil 50.
Além do percentil, outras duas medidas muito utilizadas são aquelas que dividem um conjunto de dados em quatro (quartis) e cinco (quintis) partes iguais, sendo representados da seguinte forma:
- Quartis: são representados Q1, Q2 e Q3, dividindo a série de dados em quatro partes iguais, correspondendo aos 25, 50 e 75 percentis.
- Quintis: são representados como uma medida de posição que possibilita dividir o conjunto de dados em cinco partes, correspondentes aos 20, 40, 60 e 80 percentis.
Até agora falamos sobre as medidas de localização que sempre representam o equilíbrio da amostra, entretanto, a partir do momento que encontramos o ponto médio do conjunto de dados, os demais dados estarão em torno do valor central, e são chamados de medidas de variação.
A primeira medida de variação a ser estudada é a variância (s2), que é uma expressão da variabilidade de valores em um conjunto de dados. Mede a dispersão dos dados em relação, geralmente, à média. Através dela, basicamente, sabemos se os dados estão homogêneos (quando os valores são próximos entre si) ou dispersos, com valores heterogêneos. Na pesquisa, a variância é muito usada em relação a valores que deveriam ser iguais, mas nunca serão na prática. Fatores não determinados explicitamente, mais ou menos sutis, agem de tal forma que as expressões das variáveis não sejam idênticas. Até mesmo valores obtidos de bens produzidos por aparelhos apresentam variabilidade, indicando a precisão da medida. Por exemplo, um pneu não é exatamente igual ao outro, assim como filhotes de um mesmo casal diferem entre si em muitas características, mesmo em situações completamente iguais (peso, taxa de ingestão de alimentos, velocidade de deslocamento, frequência de batimentos cardíacos, etc.).
Para o cálculo da variância, utiliza-se a seguinte fórmula: a variância de uma amostra {x1,...,xn} de n elementos é definida como a soma ao quadrado dos desvios dos elementos em relação à sua média , dividido por (n-1).
Essa variabilidade é medida em relação à média do grupo e da distância de cada valor individual em relação a essa média. Calculamos a média a partir do conjunto de cada um desses valores das distâncias.
Outra medida é o desvio padrão (dp), que é a raiz quadrada da variância, e que usamos quando olhamos para a média das nossas amostras. Pelos cálculos obtidos, no caso da variância, a unidade seria elevada ao quadrado. Para seu cálculo, basta subtrair a média de cada valor, elevar os resultados ao quadrado e somá-los. Então, dividimos o total dos quadrados pelo número de valores menos 1, ou seja, por (n-1), e extraímos a raiz quadrada.
Assimile
Tanto a variância como o desvio padrão são medidas que dão uma ideia da dispersão de uma distribuição de dados e são de extrema importância para entendermos o quanto um valor varia em torno da média.
Um valor alto para a variância (ou desvio padrão) indica que os valores observados tendem a estar distantes da média, isto é, a distribuição é mais “espalhada”. Se a variância for relativamente pequena, então os dados tendem a estar mais concentrados em torno da média, mostrando uma certa homogeneidade.
Após realizar a análise descritiva, determinar as medidas de posição e variação na apresentação gráfica por meio das análises gráficas é uma fase importante para complementar a análise exploratória, uma vez que, através dos gráficos, fica mais fácil a visualização da distribuição dos dados. Entre os tipos de gráficos, há o de setores, de barras ou colunas, de linha e histograma.
O gráfico de setores tem como objetivo apresentar informações percentuais de variáveis categóricas. Permite a visualização da participação de cada categoria em relação ao todo, em que a soma dos percentuais é 100%.
O gráfico de colunas ou barras é utilizado para as variáveis categóricas, nominais, ordinais, séries temporais e variáveis discretas, principalmente quando há diversas categorias, pois possibilita a comparação entre elas.
Outra forma de apresentação é o gráfico de linha, adequado para representar as observações ao longo do tempo, em intervalos iguais ou não, mostrando como foi o comportamento daquela variável ao longo do tempo. Tais conjuntos são chamados de séries temporais.
O histograma é uma das formas de apresentação gráfica usada para mostrar a distribuição de frequências para apresentar a distribuição de uma variável quantitativa contínua ou discreta. Este gráfico pode mostrar a distribuição de frequência e, conforme a elevação dos dados, que um intervalo é maior do que os demais.
Reflita
A estatística mostra para o pesquisador uma visão ampla sobre um determinado assunto e auxilia a responder a questões sobre a significância de uma amostra dentro de uma população, assim, depois, é possível realizar as generalizações. Contudo, ao entender os mecanismos da bioestatística, com seus testes e inferências, existe a possibilidade de manipulação dos dados para atender a alguns interesses.
Deste modo, reflita sobre essa manipulação e o que um profissional de educação física pode fazer para não infringir esse princípio ético.
Aproveite ao máximo esse conhecimento. Bons estudos!
Saiba mais
Esse vídeo analisa o mercado fitness, suas tendências, inovações e previsões de futuro.
Para visualizar o objeto, acesse seu material digital.
Faça a valer a pena
Questão 1
Estatísticas descritivas são números que resumem e descrevem um conjunto de dados. Elas apenas descrevem os dados e não representam uma generalização da amostra geral. A técnica usada para generalizar as conclusões da amostra à população é a inferência estatística.
Com essa grande quantidade de dados, a apresentação deles em seu formato bruto não permite que possam ser extraídas informações consistentes. Por outro lado, ao organizá-los previamente, possibilita-se a síntese e a simplificação.
Como podemos chamar esse processo da análise dos dados? Assinale a alternativa correta:
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Correto!
Análise estatística compreende todas as estruturas de análise baseadas nos dados.
Análise univariada é utilizada como uma forma de análise descritiva, contudo utiliza apenas as frequências das variáveis.
Análise inferencial ocorre após a realização dos testes estatísticos. De acordo com a técnica utilizada, pode-se generalizar para a população.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Questão 2
Uma das vantagens dessa forma de coleta é a possibilidade de se ter uma visão geral dos dados, além de proporcionar maior flexibilidades de análise, para que possam ser criados outros tipos de variáveis (assunto abordado na unidade anterior). Importante entendermos que os conjuntos de dados possuem nomenclaturas especificas.
Considerando o contexto, avalie as afirmativas a seguir:
- Elemento: é cada uma das unidades no estudo que são observadas. Um conjunto de dados é formado por informações sobre a variável de interesse de cada elemento, então, basicamente, é o indivíduo que está sendo avaliado em um estudo com humanos.
- Variável: é a caraterística de interesse e que se pode medir, podendo apresentar valores diferentes, dependendo do elemento.
- Observação: é a informação que a variável apresenta para cada um dos elementos especificamente.
- Caso: é o conjunto de observações de um elemento determinado.
Considerando o contexto apresentado, assinale a alternativa correta:
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Correto!
Todas as afirmações estão corretas.
Questão 3
Estatísticas descritivas são números que resumem e descrevem um conjunto de dados. Elas apenas descrevem os dados e não representam uma generalização da amostra geral. A técnica usada para generalizar as conclusões da amostra à população é a inferência estatística.
A tabela a seguir representa a distribuição de frequências dos salários em um certo mês de um grupo de 50 professores, em quatro filiais de uma academia. Determine o salário médio dos empregados nesse mês.
| Lorem ipsum | Lorem ipsum | Column 3 | Column 4 |
|---|---|---|---|
| Filial | Salário do mês R$ | Número de professores | |
| 1 | 1000 – 2000 | 20 | |
| 2 | 2000 – 3000 | 18 | |
| 3 | 3000 – 4000 | 9 | |
| 4 | 4000 - 5000 | 3 |
Assinale a alternativa que apresenta o resultado correto:
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Correto!
Deve-se realizar a média de cada uma das filiais:
1: 1.500.
2: 2.500.
3: 3.500.
4: 4.500.
Com esses resultados, multiplica-se o valor médio de cada filial pela quantidade de funcionários com valor do salário. Em seguida, somam-se todas os resultados das filiais, dividindo pelo total de funcionários. O resultado é R$ 2.400,00.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Referências
SILVA, R. B. Construindo conhecimento de média, mediana e moda: uma investigação docente. Cadernos de Pesquisa, v. 25, n. 2, p. 187-206, 2018.