Comentários
Falhas em sistemas computacionais são respostas incorretas em relação ao que foi projetado como saída. Essas falhas podem ser geradas por fator humano, meios de transmissão, hardware, lógico (software), entre outros. (Tanenbaum 1997)

Fonte: Shutterstock.
Deseja ouvir este material?
Áudio disponível no material digital.
A empresa T2@T Visão é renomada no ramo de armação para óculos graças à qualidade dos seus produtos, diversos dos quais atualmente são comercializados na Europa. A sua rede interna não possui muitos serviços e dispositivos, sendo considerada uma rede pequena.
Para aumentar as vendas, a T2@T Visão faz parceria com algumas empresas de vendas on-line. Para isso, a base de dados do servidor de arquivos da T2@T Visão é compartilhada com essas companhias. Porém, nos últimos cinco dias, os parceiros comerciais informaram ao setor de informática algumas falhas apresentadas:
Considerando que um e-commerce deve ficar disponível 24 horas por dia, apresente em forma de relatório ao gerente da T2@T Visão o cálculo de tempo médio entre falhas (MTBF) e tempo médio para reparos (MTTR). Com isso será possível informar para a empresa o tempo total durante o qual o servidor ficou indisponível durante os cinco dias em que foram relatadas as falhas, o que, então, permitirá que seja tomada alguma medida para eliminar ou diminuir a ocorrência de falhas.
Ao efetuar tais cálculos em decorrência das falhas, você poderá efetuar um planejamento de tempo de parada para manutenção, possibilitando mitigar as falhas recorrentes nas redes de computadores.
Pronto para mais esse desafio?
Certamente, ao utilizar o serviço de telefonia celular, você já ouviu o eco da sua voz; ou ainda, ao assistir um noticiário pela televisão, percebeu que o áudio e o vídeo perdem o sincronismo entre si. Esses sintomas que causam as degradações dos serviços de comunicação de dados são mais comuns do que pensamos.
Segundo Comer (2007), qualquer sistema de comunicação de dados é suscetível a falhas e erros. Pode ocorrer em dispositivos físicos ou em transmissão. Mesmo quando são feitos exaustivos testes de erros ou de stress de rede, tais ocorrências ainda podem aparecer nas estruturas das redes de computadores. Os erros de transmissão são divididos em três categorias:
Em redes com uma grande infraestrutura e/ou com diversos serviços disponibilizados aos usuários, é prudente fazer teste de stress, sendo possível determinar:
Basicamente, são softwares que introduzem uma quantidade de pacotes de tipos e tamanhos diferentes, para que sejam determinados alguns limites e capacidades da rede.
Para a compreensão da taxa de erros encontrados nas redes de computadores, é necessário que conheçamos o Teorema de Shannon. Segundo Carissimi (2009), em 1984 o cientista americano Claude Shannon publicou as bases matemáticas para determinar a capacidade máxima de transmissão por um canal físico com uma banda passante, em uma determinada relação sinal/ruído. (Neste momento nos atentaremos apenas para os conceitos, pois os cálculos são tratados nos estudos de telecomunicações.)
Os erros ocorridos na comunicação de dados não podem ser eliminados por completo, porém aqueles relacionados à transmissão podem ser facilmente detectados, permitindo assim que sejam corrigidos automaticamente. Para efetuar o tratamento desses erros existe uma relação de custo-benefício, pois é adicionada uma sobrecarga no processo de transmissão. Os erros de transmissão podem afetar os dados de três formas, conforme demonstrado no Quadro 4.1.
| TIPO DE ERRO |
DESCRIÇÃO |
|---|---|
| Erro em um único bit |
Apenas um bit sofre uma alteração e os demais permanecem preservados. A degradação do serviço ocorre por um período bem curto. |
| Erro em rajada |
Vários bits sofrem alterações. A degradação do serviço ocorre por um longo período. |
| Indefinido |
A transmissão que chega ao receptor é ambígua (valores fora do escopo). Podem ocorrer diversos períodos de degradação do serviço. |
Para possibilitar a compreensão do Quadro 4.1, dois termos devem ser mais bem discutidos: “erro em um único bit” e “erro em rajada”.
Observe na Figura 4.5 a seguir quando o erro ocorre em um único dos bits enviados:
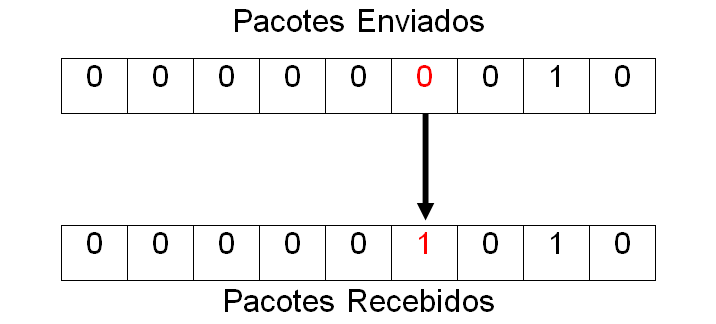
Conforme pode ser verificado, o quinto bit, o mesmo que foi transmitido com o valor “0”, foi recebido pelo valor “1”. O erro de um único bit (single-bit-error) causa uma degradação com menor duração, porém, dependendo do que está sendo transmitido, pode ser mais ou menos degradante, por exemplo: se o erro acontecer quando se está assistindo a um filme por streaming, ocorre um travamento momentâneo, ou seja, uma parte da cena é pulada. Por sua vez, se o erro de transmissão ocorre ao tentar acessar um site (transmissão elástico), este apresentará, por exemplo, algum erro de carregamento.
Agora observe na seguinte Figura 4.6 a demonstração de quando os erros ocorrem em rajadas:
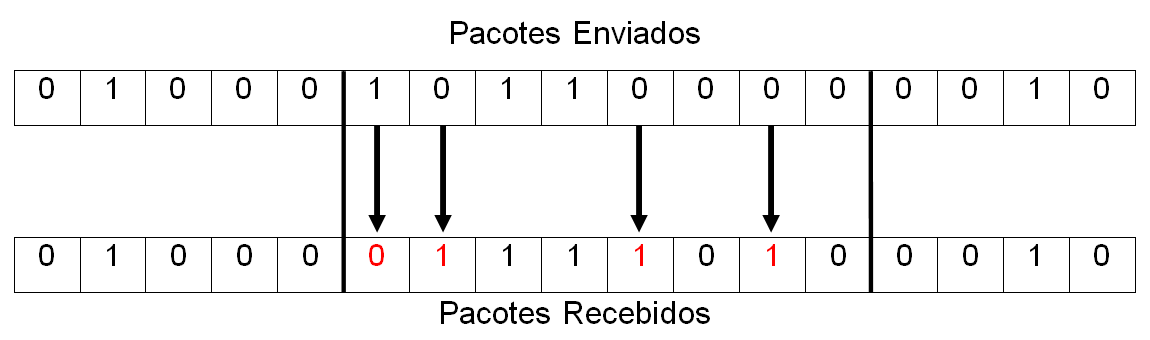
Não necessariamente os erros em rajada ocorrem em bits consecutivos, conforme pode ser observado na Figura 4.6. Como são transmitidos em rajadas, para contabilizá-los, após a ocorrência de um erro, agrupa-se um bloco de oito bits. Na Figura 4.6 pode-se notar que ocorreram quatro erros.
Os erros em rajada têm um tempo de duração maior em relação ao erro em único bit. Normalmente a degradação do serviço pode ser sensível nas transmissões tanto streaming, quanto elástico (acesso a sites, por exemplo).
A comunicação utilizada em jogos on-line é feita em rajada; na ocorrência de erros, em casos mais leves pode apenas apresentar uma paralisação temporária da cena em que o jogo esteja se passando, e, após um tempo retoma-se a partida. Nos casos extremos, quando os erros ocorridos nas transmissões em rajada se repetem continuamente, a conexão pode ser perdida.
As degradações de jogos on-line são muito comuns, pois os erros e as falhas podem ocorrer na transmissão dos dados, no processamento da aplicação no servidor, entre outros casos.
Assim que os erros são detectados, é necessário efetuar a correção deles. No entanto, para que isso ocorra, o número de bits corrompidos deve ser determinado. Nesse caso, são possíveis dois métodos de correção de erros:
Certamente todos nós, ao utilizarmos algum serviço, passamos por casos em que o resultado gerado não retornou como o esperado. Tais acontecimentos são chamados de falhas. Esse tipo de ocorrência está muito presente na vida das pessoas: quando não se consegue efetuar um saque no caixa eletrônico; quando a cancela da praça de pedágio não levanta na cobrança automática (Sem Parar, Conect Car, etc.).
Tanenbaum (1997) define que as falhas em sistemas computacionais são respostas incorretas em relação ao que foi projetado como saída, podendo ser definidas por alguns especialistas como defeito. Essas falhas podem ser geradas por fator humano, meios de transmissão, hardware, lógico (software), entre outros.
Para auxiliar os profissionais de tecnologia da informação a prever as falhas de hardware, por meio de análise estatística de dados históricos dos dispositivos de uma rede, são utilizadas as técnicas:
Para auxiliar a compreensão, vejamos um exemplo:
Qual é o tempo encontrado entre as falhas? Qual é o tempo necessário para efetuar os reparos?
Para o cálculo do tempo médio entre as falhas, temos que:
Com isso, é possível determinar o tempo de manutenção de cada uma das paradas:
Ou seja, dessa forma é possível prever, por meio dos cálculos efetuados com os dados históricos/estatísticos, que a cada duas horas o servidor apresentará uma falha e que serão necessários quinze minutos para efetuar a sua manutenção. Dessa forma, o “SQL_SERVER” ficará indisponível por duas horas, durante o turno de trabalho de nove horas.
Embora as observações históricas e os tratamentos estatísticos do MTBF e MTTR possam prever os tempos decorrentes de falhas, o tempo de reparo e manutenção, por que, ainda assim, os serviços de internet, bancários, entre outros utilizados no dia a dia, apresentam falhas?
Durante os primeiros anos, a utilização das redes era destinada apenas para pesquisas, trocas de mensagens e compartilhamento de alguns recursos, como as impressoras. Nessas condições, a segurança nunca foi uma preocupação. Com o advento de maior oferta de internet pelas operadoras e consequentemente um maior número de dispositivos, tais implicações passaram a ser uma ameaça para as pessoas e empresas.
Segurança de redes é um assunto muito abrangente, razão pela qual, nesta seção, vamos nos concentrar em criptografia, logs e controle de acesso.
Segundo Tanenbaum (1997), quatro grupos contribuíram para o surgimento e o aprimoramento dos métodos de criptografia: os militares, os diplomatas, as pessoas “comuns” que gostam de guardar memórias e os amantes. O maior volume de contribuição adveio dos militares, uma vez que eles tinham interesses como estratégia de comunicação em período de guerra.
Basicamente, o processo consiste em transformar uma mensagem de texto com uma chave parametrizada, cuja saída é um texto cifrado, com o uso de um algoritmo criptográfico. Se a mensagem for capturada e o interceptor não possuir a chave, este não conseguirá fazer o processo inverso, que possibilite ler o conteúdo da mensagem. Neste momento vale a pena conceituar três termos:
Tanenbaum (1997) sugere um modelo matemático para representar o processo de criptografia, em que:
onde:
P → denota o texto simples.
k → chave para criptografia.
C → texto cifrado.
Para o processo inverso (descriptografia), temos que:
Essas notações sugerem que as letras “E” e “D” são funções matemáticas. Dessa forma, tanto na função de criptografia, quanto na de descriptografia há uma chave aplicada a uma função matemática.
Outra forma de proteger uma mensagem é utilizar a técnica de esteganografia, que pode ser definida como a arte de esconder dentro de outro arquivo aparentemente inofensivo alguma mensagem; se esta for interceptada, não será possível detectá-la.
Como as funções matemáticas podem assumir infinitos valores e variáveis, vamos nos concentrar nesse momento nos conceitos relacionados à “chave”.
Segundo Tanenbaum (1997), para a compreensão do conceito de chave no tocante de criptografia é necessário o entendimento do princípio de Kerckhoff. Esse nome é em homenagem ao militar Auguste Kerckhoff que em 1883, publicou que: “Todos os algoritmos devem ser públicos; apenas as chaves são secretas.” (KERCKHOFF, 1883 apud TANENBAUM, 1997, p. 546).
Dessa forma, podemos compreender que o algoritmo não necessita ser secreto ou sigiloso. Os fatores relacionados à segurança devem estar nas chaves, para isso é sugerido que possuam os tamanhos e aplicações conforme demonstrado no Quadro 4.2:
| Tamanho da Chave |
Aplicação |
|---|---|
| 64 bits | Correio eletrônico, mensagens de chat, entre outros meios de comunicação instantânea que não exijam nível específico de segurança. |
| 128 bits | Uso comercial, empresas, universidades, etc. |
| 256 bits | Comunicação de interesse governamental. |
Os tamanhos das chaves mudam a cada ano, conforme as quebras se tornam possíveis com o aumento do poder computacional. Em todos os tamanhos das chaves, espera-se que a garantia do sigilo das informações em sistemas computacionais se dê na presença de um algoritmo forte, porém público, e uma chave de longo comprimento.
Segundo Tanenbaum (1997), são ferramentas importantes para os administradores de redes, pois são recursos de fácil implementação que podem fornecer um histórico para análise. Os geradores de logs devem obedecer a uma regra simples: manter os dispositivos sincronizados ao servidor NTP. Tais registros de logs devem ser armazenados em servidores local ou remoto e as suas informações podem ser acessadas on-line e/ou off-line.
Destacamos que não basta gerar e armazenar os logs se algumas práticas de monitoramento não forem seguidas:
Segundo Tanenbaum (1997), também conhecida como NAC (Network Access Control), é um recurso muito importante para auxiliar no gerenciamento das questões relacionadas à segurança. Tais ferramentas auxiliam o administrador de redes nas seguintes tarefas:
Tais técnicas permitem que os dispositivos e usuários que necessitem conectar-se à rede sejam identificados e, se possuírem credenciais, sejam autorizados a fazê-lo, sendo, portanto, possível verificar o status e a atualização de antivírus, as aplicações, os softwares, etc.
Conhecer todos os conceitos e todas as aplicações abordados nesta seção de ensino garantirá que a rede atenda aos padrões de qualidade desejados, possibilitando o cálculo de tempo de manutenção, a utilização dos métodos de criptografia adequados para cada caso, mostrando, para isso, a importância de se manter o controle de acesso para a garantia da segurança da rede e dos usuários.



