Comentários
Segundo Tanenbaum (1997), em diversas situações os engenheiros de redes necessitam avaliar desde a estrutura da rede até os dispositivos individualmente, para então realizar testes probatórios de qualidade.

Fonte: Shutterstock.
Deseja ouvir este material?
Áudio disponível no material digital.
A empresa T2@T Visão, especializada em armação para óculos, tem como característica fabricar produtos de qualidade internacional. Atualmente, grande parte da sua produção é comercializada na Europa. Para ampliar as suas vendas, a companhia compartilha a sua base de dados com alguns parceiros comerciais, que fazem a revenda dos seus produtos.
Recentemente a gerência solicitou o cálculo de tempo médio entre as falhas (MTBF – Mean Time Between Failures) e o tempo médio para reparos (MTTR – Mean Time To Repair), chegando à conclusão de que o serviço fica indisponível uma hora por dia. O tempo anual que a base de dados deve ficar disponível é de 8000 horas (MTTF - Mean Time to Failure).
O gerente solicitou um relatório com o demonstrativo do cálculo de disponibilidade da base de dados, pois o contrato prevê que ela precisa ser maior que 90%, caso contrário a T2@T Visão deve pagar multa aos parceiros comerciais.
Caro aluno, efetuar os cálculos de disponibilidade de serviços e/ou dispositivos de uma rede de computadores possibilita o planejamento preventivo a fim de garantir o funcionamento sem que haja interrupção.
Vamos ajudar o gerente da T2@T Visão efetuando os cálculos de disponibilidade?
Todos nós já utilizamos algum meio de comunicação ou um serviço de rede, que não conseguiu atender com a qualidade esperada. Para que possamos parametrizar alguns serviços, é necessário conhecermos quais são os indicadores utilizados nas redes de computadores a fim de garantir a qualidade e a disponibilidade.
Talvez uma das maiores dificuldades encontradas é ajustar os parâmetros de desempenho da rede para que possam suprir as necessidades. Segundo Tanenbaum (1997), em diversas situações os engenheiros de redes necessitam avaliar desde a estrutura da rede até os dispositivos individualmente, para então realizar testes probatórios de qualidade.
Normalmente os testes de desempenho são feitos por meio da injeção de um determinado tráfego na rede, permitindo assim que o administrador de rede analise as saídas. Vários aspectos podem ser observados, tais como, entre outros:
Um software muito utilizado por administradores de redes para analisar vazão, latência, jitter e perda de pacotes é o Iperf (Jperf em Linux). Esse programa faz a análise de rede e do seu desempenho, por meio das ferramentas disponíveis e configuradas, para enviar pacotes de tamanhos variáveis conforme o experimento a ser realizado.
Ao utilizar esses tipos de ferramentas, é possível compreender quais dados são mais/menos utilizados, qual é o horário de maior consumo dos recursos, entre outras coisas. Isso possibilita a compreensão do perfil dos usuários e adequação da rede a fim de atender aos serviços prioritários para determinada rede.
Quando pensamos no quesito “desempenho da rede”, não importa muito o tipo de serviço que se esteja utilizando. Porém, ao estudamos os protocolos de redes, principalmente o TCP/IP e UDP, vimos que todos eles têm funcionamento, tamanho e, consequentemente, ocupam mais/menos recursos da rede.
Tenambaum (1997) define que as redes devem ser reconfiguráveis graças ao fato de os perfis de tráfego mudarem com muita frequência. Para a garantia da continuidade dos serviços da rede e a manutenção da qualidade, os administradores de redes devem permitir:
Dessa forma, ao conhecer o perfil do tráfego da rede, é possível adequar os recursos às necessidades, ou ainda manter o equilíbrio necessário para ter um nível de qualidade adequado.
Segundo Forouzan (2006), a vazão em redes de computadores pode ser definida como a quantidade de dados transferidos entre dispositivos (da mesma rede, ou de redes diferentes), ou mesmo a quantidade de dados processados em determinado tempo. Normalmente é expressa em bits por segundo (bps). “Ou seja, se considerarmos o ponto como sendo um plano que secciona o meio, o throughput é o número de bits que atravessa esse plano”. (FOROUZAN, 2006, p. 90)
Os fatores que interferem na vazão são:
Observe a Figura 4.8, em que a vazão é medida por meio do software Iperf.
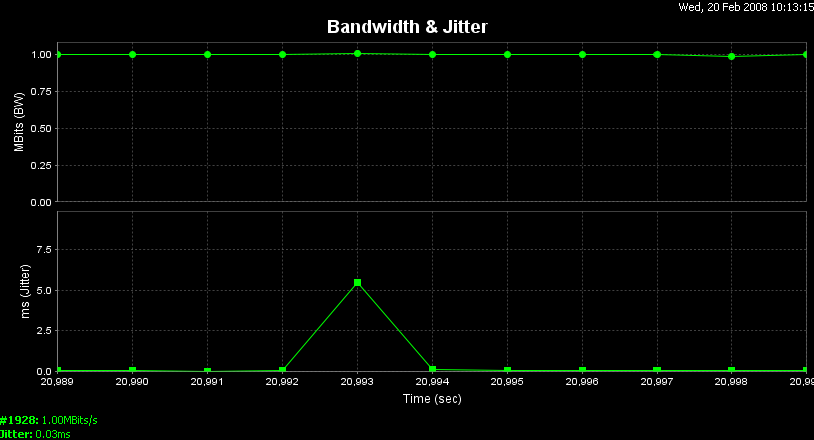
Na parte superior da Figura 4.8, pode-se observar que a rede está permitindo a utilização de 100% da capacidade de sua vazão.
Dessa forma, podemos concluir que a vazão poderia ser descrita como a velocidade em que os dados realmente trafegam pela rede. Essa taxa de transferência pode ser menor do que a largura de banda, devido a perdas e atrasos.
Segundo Tanenbaum (1997), em razão de os roteadores não terem a capacidade de armazenamento de pacotes infinita, após o esgotamento, os pacotes são descartados. À medida que a rede cresce ou a exigência de processamento aumenta devido às aplicações, o nodo passa a ter mais solicitações e, consequentemente, pode ocorrer perda de pacotes.
Para melhor compreensão de que forma a perda de pacotes pode degradar os serviços, na Figura 4.9 é demonstrado um teste com base no qual é possível observar as perdas de pacotes ocorridas em uma rede.
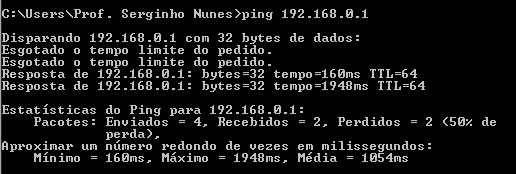
Propositalmente, utilizando uma conexão sem fio a dez metros do roteador (com o sinal atravessando quatro paredes), houve dois pacotes perdidos. Em outras palavras, 50% do serviço ficou indisponível para os usuários.
Agora observe a Figura 4.10 em que o teste foi feito a dois metros do roteador.
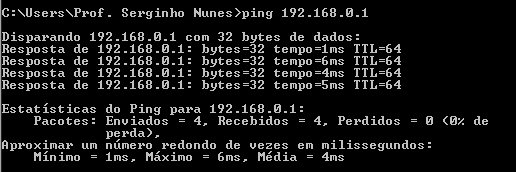
Nesse segundo cenário pode-se observar que 100% dos pacotes foram recebidos.
Segundo Carissimi (2009), em redes de computadores, latência é o intervalo de tempo entre o momento que o emissor enviou o pacote e o recebimento da confirmação do pacote por parte do receptor. O tempo que o receptor gasta no processamento do pacote não deve ser utilizado no cálculo da latência.
A latência pode ser considerada:
Latência = Tempo de transmissão + Tempo de propagação
Em que:
Segundo Kurose (2006), há dois outros tipos de atrasos que podem provocar latência: o tempo de processamento e o tempo de enfileiramento (gargalos). No entanto, esses dois tempos só podem ser aferidos em uma rede com utilização de tráfego significativamente elevado.
No experimento utilizado para demonstrar a perda de pacotes (observe nas Figuras 4.9 e 4.10), temos um parâmetro de saída do teste com valores para “mínimo”, “máximo” e “média”, organizados conforme o Quadro 4.3.
| Valores |
Experimento 1 |
Experimento 2 |
|---|---|---|
| Mínimo | 160 ms | 1 ms |
| Máximo | 1948 ms | 6 ms |
| Média | 1054 ms | 4 ms |
Foi possível compreender numericamente os experimentos ao observarmos os tempos de propagação dos pacotes.
O aumento da latência (atraso) e a perda de pacotes nas transmissões sofrem interferências devido, entre outros fatores, à:
É fato que esses tipos de ocorrências podem se mostrar como um dos maiores degradadores dos serviços encontrados nas redes de computadores.
Segundo Comer (2007, p. 43), “o jitter pode ser definido como a variação no tempo e na sequência de entrega dos pacotes (Packet-Delay Variation) devido à variação da latência (atrasos) na rede”. A influência do jitter é mais sensível para a qualidade de serviço quando se tem a necessidade da garantia na entrega dos pacotes em períodos definidos.
O jitter é analisado na periodicidade na transmissão dos pacotes, como também na variação da entrega dos pacotes, conforme pode ser observado na Figura 4.11:
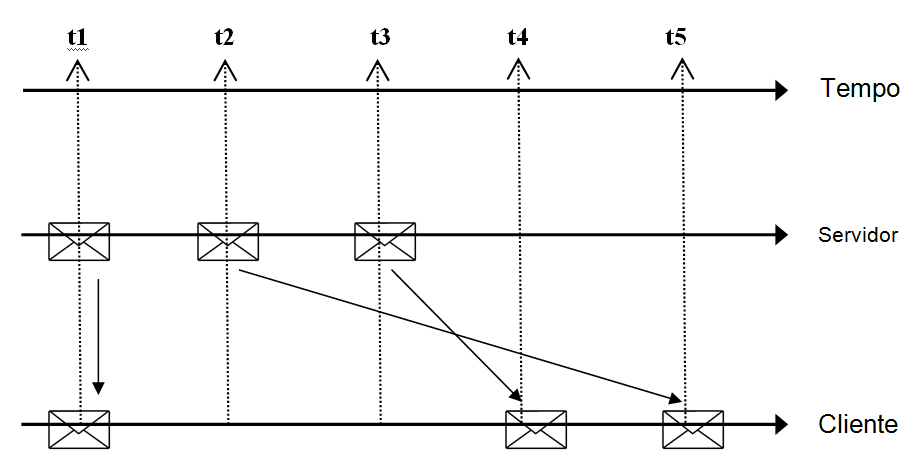
Para compreensão da Figura 4.11, observe o esquema a seguir:
Para que as mensagens trocadas entre os dispositivos possam chegar ao seu destino, são necessários protocolos, equipamentos, meios de transmissão, entre outras coisas.
Quando os pacotes são transmitidos e chegam em ordem trocada (jitter), podemos considerá-los como perdidos, assim como ocorre na perda de pacotes?
Segundo Comer (2007), as redes de computadores são compostas por diversos equipamentos, como nodos, computadores, servidores, cabeamentos, entre outros, cada um dos quais é um sistema suscetível a falhas. Ou seja, é a descrição da capacidade que equipamentos e redes possuem de forma contínua (sem que haja interrupção), por um período.
Vamos relembrar dois conceitos que já estudamos:
Para que seja possível calcular a disponibilidade, é necessário compreender o tempo médio para falha (MTTF – mean time to failure): tempo de vida de uma rede que compreende os períodos alternados de operação de falhas.
Com isso, é possível efetuar o cálculo de disponibilidade, por meio da função de frequência com que as falhas ocorrem e o tempo necessário para reparo, em que:
Para exemplificarmos uma aplicação, imagine que uma rede possua um MTTF de 8.000 horas de operação anual e um MTTR de 36 horas anual. Nesse caso:
Ou seja, a disponibilidade da rede é de 99,5% ao ano.
O software Iperf permite realizar algumas medições nas redes a fim de se conhecer mais sobre a estrutura. O trabalho intitulado Análise de impacto na transição entre os protocolos de comunicação IPv4 e IPv6, de Nunes (2013), demonstra uma comparação de latência, throughput, jitter e perda de pacotes em uma rede IPv4 pura, IPv6 pura e pilha dupla.
Segundo Tanenbaum (1997), qualidade de serviço em redes de computadores pode ser definida como um conjunto de regras, mecanismos e tecnologias que tem o propósito de utilizar os recursos disponíveis de forma eficaz e econômica. Além disso, os fatores que determinam diretamente a qualidade de transmissão são: latência, jitter, perda de pacotes e largura de banda disponível.
Para que sejam atendidas às necessidades das redes, são utilizados dois modelos de QoS, entre os quais temos:
Qualidade dos serviços, disponibilidade, capacidade de processamento e armazenamento do provedor de serviços são determinados pelo SLA (service level agreement – acordo de nível de serviço). Este tem como função especificar os níveis de desempenho em contrato de serviço.
As configurações de equipamentos como computadores, roteadores, switchs, impressoras, entre outros, dependem de algumas características, como:
Um exemplo de configuração de equipamentos é a utilização do VLAN Trunk Protocol. Trata-se de um protocolo de camada 2, desenvolvido pela Cisco, para configuração de VLANs, facilitando, assim, a sua administração. Mas o que é uma VLAN?
Fillippetti (2008) mostra que VLAN é definida como rede local virtual (virtual lan network). Trata-se de uma maneira de criar sub-redes de forma virtual. Se feita em switchs, cada uma das interfaces pode ser uma VLAN e ter o seu próprio domínio de broadcast. Observe o exemplo na Figura 4.12:
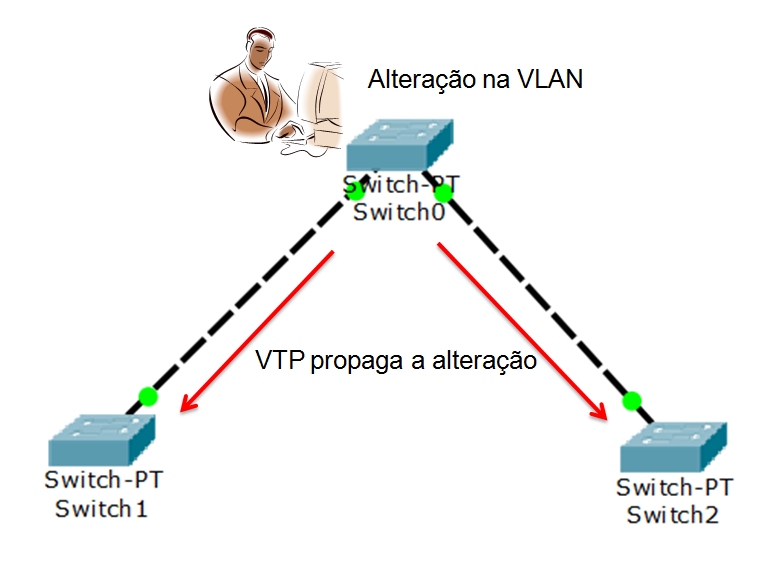
Basicamente, o VTP (VLAN Trunk Protocol) cria uma estrutura do tipo cliente-servidor, em que as alterações obrigatoriamente são feitas no servidor, que, por sua vez, posteriormente as replica aos clientes. Tal técnica é largamente utilizada pelos administradores de redes.
Ao discutirmos os assuntos abordados nesta seção de aprendizagem, podemos compreender alguns parâmetros que devem ser observados pelos administradores de redes para que se possam garantir a qualidade dos serviços e a disponibilidade da rede. Além disso, pode-se compreender também a forma pela qual a configuração e a padronização de procedimentos podem auxiliar os profissionais de tecnologia da informação, no gerenciamento das redes de computadores.
CARISSIMI, A. Redes de computadores. Instituto de Informática UFRGS. Porto Alegre: Bookman, 2009.
COMER, D. E. Computer and networks internet with internet applications. São Paulo: Artmed, 2007.
FILIPPETTI, M. A. CCNA 4.1: Guia completo de estudos. Florianópolis: Visual Books, 2008.
FOROUZAN, A. Comunicação de dados e redes de computadores. Porto Alegre: Bookman, 2006.
G1. Brasil é o 4º consumidor de games, mas mercado carece de mão de obra. Disponível em: https://glo.bo/2qAxhbS. Acesso em: 27 nov. 2017.
KUROSE, J. F. Redes de computadores e a internet: uma abordagem top-down. 3. ed. São Paulo: Pearson, 2006.
TANENBAUM, A. S. Redes de computadores. 4 ed. Rio de Janeiro: Campus, 1997.
WORD REFERENCE. Sniff. Disponível em: https://bit.ly/2NpuQ52. Acesso em: 27 nov. 2017.



