



lorem ipsum dolor sit amet
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nunc dignissim euismod urna tincidunt sagittis. Vivamus id vehicula eros, non scelerisque eros.

Fonte: Shutterstock.
Deseja ouvir este material?
Áudio disponível no material digital.
Convite ao estudo
Caro estudante, a primeira unidade deste livro foi idealizada para que, a partir do entendimento dos fundamentos de Probabilidade e Estatística, você se sinta seguro para aplicar de forma prática os principais conceitos abordados, tornando-se cada vez mais apto para desempenhar funções em um dos mercados mais promissores da atualidade: o de Análise de Dados. Além da crescente demanda por profissionais que dominem os diversos elementos que permeiam estas duas disciplinas, uma habilidade tão requisitada quanto a teoria são os conhecimentos relacionados à programação, especialmente por meio da Linguagem R.
Nesse sentido, na Seção 1, abordaremos os aspectos iniciais e introdutórios da Análise de Dados, apresentando como a Estatística e a Probabilidade convergem para uma relação sinérgica que configura um importante mecanismo de Análise. Além disso, também serão falaremos um pouco sobre as principais ferramentas computacionais, como o Python e o R, que facilitam o nosso trabalho tanto nas análises propriamente ditas, quanto na apresentação dos resultados.
Na segunda seção, iremos avançar um pouco mais nos métodos estatísticos, distinguindo os conceitos Estatística Inferencial e Descritiva. Também desenvolveremos alguns aspectos cruciais, que estarão sempre presentes em nosso dia a dia: população, amostra e amostragem. Em seguida, falaremos um pouco das séries estatísticas, integrando o nosso primeiro exercício prático, em que utilizaremos a linguagem R.
Por fim, na terceira seção, focaremos nos métodos probabilísticos, abordando aspectos teóricos de Probabilidade, espaço amostral e conceitos de probabilidade condicional. Assim como na segunda seção, trabalharemos unindo a teoria e prática, por meio de exercícios realizados em linguagem R.
Após concluirmos estas três seções, entenderemos os conceitos teóricos e as diversas possibilidades de aplicações das ferramentas de Probabilidade e Estatística para Análise de Dados.
Que comece a nossa jornada!
Praticar para aprender
Nesta seção, trabalharemos alguns conceitos introdutórios sobre Análise de Dados, contextualizando brevemente a história das revoluções vividas na humanidade e a chegada aos dias atuais, tempo em que vivemos a Quarta Revolução Industrial. Em seguida, entenderemos um pouco mais sobre as diferenças conceituais entre dado, informação e conhecimento, além de apresentarmos a importância da Probabilidade e da Estatística no contexto deste livro. Por fim, introduziremos as principais ferramentas, em termos de software e linguagens de programação, utilizadas para a Análise de Dados.
Dominar estes conceitos, além de fundamental para a compreensão do conteúdo deste livro, também é de suma importância para o mercado de trabalho, considerando que as competências ligadas à Análise de Dados são cada vez mais exigidas em grande parte das profissões.
Para aqueles que trabalham ou planejam trabalhar diretamente como analistas de dados, independente da área de aplicação, os conceitos apresentados nesta primeira seção farão parte de suas atividades profissionais diárias, sendo imprescindível que estejam bem fixados. Para as demais profissões, ainda que operem de forma indireta com a Análise de Dados, conhecer os principais fundamentos é de grande importância para que se tenha uma boa desenvoltura em um possível contato com a área.
Considerando que os dados estarão presentes em praticamente todas as áreas do conhecimento, estar confortável em relação às diversas possibilidades que existem na Análise de Dados é um passo dado hoje, para que um mundo de oportunidades se abra no futuro.
Você é gerente de RH de uma empresa familiar. O presidente da organização frequentemente toma decisões baseadas em seus conhecimentos adquiridos ao longo da vida, além de confiar sempre em sua intuição. No entanto, ultimamente a empresa tem sofrido com algumas decisões realizadas de forma equivocada, trazendo alguns resultados financeiros e não-financeiros negativos. O presidente acredita que os funcionários da cidade de São Paulo possuem salários superiores aos daqueles do Rio de Janeiro, tomando por base a remuneração conferida ao cargo de assistente administrativo, nos valores de R$ 2.875,00 e R$ 2.500,00, respectivamente. Para sanar o problema, o presidente propõe um reajuste salarial de 15% para todos os funcionários do Rio, valor equivalente à diferença percentual entre os dois salários. No entanto, como especialista da área, você entende que esta diferença não existe na prática, especialmente quando se avaliam os demais cargos, alguns fatores locais e os impactos financeiros para a companhia. Conhecendo a importância da análise de dados, você deverá convencer o seu presidente para utilizar algumas ferramentas de estatística e probabilidade, com o intuito de avaliar se o reajuste proposto se justifica.
Caminhemos juntos para uma primeira imersão!
conceito-chave
Historicamente, a existência humana está associada a diversos processos revolucionários que guiaram a sociedade para um determinado avanço tecnológico. Um destes primeiros processos dos quais temos conhecimento foi a Revolução Neolítica, que permitiu ao Homo Sapiens, até então nômade, a fixação de uma residência, por meio da agricultura. Há cerca de 10.000 anos, plantar, cultivar e colher se tornou a principal tecnologia da época, possibilitando aos humanos se concentrarem em atividades diferentes da caça e coleta (HARARI, 2019).
A Revolução Neolítica, portanto, foi fundamental para que a humanidade caminhasse rumo aos processos subsequentes, como as revoluções industriais vivenciadas a partir do século XVIII. A inserção de máquinas no processo de tecelagem inglês, até então artesanal, foi o marco que deu início à Primeira Revolução Industrial. A Segunda Revolução Industrial, por sua vez, caracterizou-se pela expansão da Primeira para outros países, além do surgimento da indústria do petróleo, aço e eletricidade (Hobsbawm, 2015).
Em meados do século XX, no período pós-guerra, iniciou-se um momento de corrida tecnológica, com destaque para as indústrias aeroespacial, nuclear, genética, da telecomunicação, entre outras (Hobsbawm, 1995). Era o princípio da Terceira Revolução Industrial, frequentemente associada ao processo de globalização.
A Terceira Revolução Industrial é o fator precursor do momento que se vive na atualidade: o mundo está passando por um processo de revolução de dados, também denominado de Quarta Revolução Industrial e Indústria 4.0. Com o advento de novas tecnologias digitais, como o Big Data, a Internet das Coisas, o Machine Learning, a Computação em Nuvem, entre outras, o fator revolucionário, que outrora foram a máquina à vapor, o petróleo, a eletricidade, a computação etc., se caracteriza por um componente principal: os dados.
Um dado, por si só, é pouco útil. Ao pegarmos um Cadastro de Pessoa Física (CPF), por exemplo, pouco se pode tirar, além de um conjunto de, no máximo, onze números. No entanto, quando processamos este dado, cruzando-o com algum outro, iniciamos o processo de obtenção/produção de informação, que é o objetivo da análise de dados. Quando cruzamos, por exemplo, o número do CPF de uma pessoa com o seu histórico de inadimplência, teremos a informação de que aquele indivíduo é um bom pagador ou não.
Exemplificando
Da mesma forma, na área da saúde, temperatura corporal de uma pessoa pode até indicar a presença de febre ou não. Mas para sabermos, por exemplo, se o caso pode ser um quadro sintomático de Covid-19, precisaremos de mais dados, que cruzados e processados, nos darão tal informação. Quando olhamos para área de gestão empresarial, uma data, como 24/08/2021, pouco pode dizer sobre determinado assunto. Porém, quando associamos esse dado a algum outro, criamos uma informação, que pode dar origem, por exemplo, a um Key Performance Indicator (KPI).
Após a etapa de processamento de dados, inicia-se uma etapa de avaliação, reflexão e interpretação da informação, que será a base para a geração do conhecimento, conforme síntese expressa no Quadro 1.1.
Quadro 1.1 | Definições de Dados, Informação e Conhecimento
Fonte: Davenport e Prusak (1997, p. 9).
| Dados | Informação | Conhecimento |
|---|---|---|
| Observações simples sobre o estado do mundo. • Facilmente estruturados • Facilmente captados por meio de máquinas • Frequentemente quantificado • Facilmente transferido |
Dados dotados com relevância e propósito. • Requer unidade de análises • Necessita de consenso de significado • Necessário reflexão humana |
Informação valiosa da mente humana. Inclui reflexão, síntese e contexto. • Difícil de estruturar • Dificuldade de capturar por meio de máquinas • Geralmente tácita • Difícil de transferir |
A esta definição proposta por Davenport e Prusak em 1997, soma-se um novo conceito, denominado dados não-estruturados. Os dados estruturados são representados por fatores como endereços, nomes, telefones, peso, altura, quantidades, ou seja, tudo aquilo facilmente apresentado em uma planilha. Por outro lado, os dados não-estruturados referem-se a áudios, imagens, e-mails, discursos, avaliações, ou seja, tudo aquilo que não pode ser representado e estruturado em planilhas. No entanto, apesar de diferentes, ambos os tipos de dados são de grande utilidade e compõem o processo de mudança de patamar tecnológico das últimas décadas.
Reflita
No dia a dia, frequentemente utilizamos de forma equivocada alguns conceitos definidos cientificamente. É o caso, por exemplo, do emprego das palavras dado e informação. Por quantas vezes nos referimos como dados aquilo que na verdade é informação e vice-versa. Pense em alguns casos. Por mais que esta alteração de significado não traga, necessariamente, algum prejuízo, é importante para nós termos estes conceitos bem definidos.
Pode-se dizer, portanto, que a revolução dos dados trouxe consigo uma transição para uma sociedade de informação, onde se tomam decisões mais embasadas e assertivas, de modo a se diminuir a ocorrência de erros, em um processo denominado data driven decision making, ou seja, decisões tomadas com base em dados. No entanto, para que estas decisões sejam bem fundamentadas, é de suma importância que estejam apoiadas em algum aparato técnico-científico, que, para a área de dados e informação, denomina-se Data Science, ou seja, Ciência de Dados.
A Ciência de Dados é uma área do conhecimento recém-criada que conversa com diversas outras disciplinas tradicionais, como Estatística, Matemática, Tecnologia da Informação e Inteligência de Negócios. Seu campo de ação estende-se desde o planejamento de coleta de dados, até armazenamento, tratamento, processamento e análise. Por ser de uma área nova, suas definições e conceitos ainda estão sendo criados, porém, de forma razoável, é possível compreender a Ciência de Dados como uma área interdisciplinar que, a partir do estudo dos dados e da informação, configura e parametriza os métodos e ferramentas para análise de dados e tomada de decisão. A Figura 1.1 representa as relações entre as principais disciplinas que compõe a Ciência de Dados. O diagrama de Venn em questão foi inicialmente idealizado por Drew Conway, um cientista de dados americano e criador de uma startup na área de tecnologia. Apesar de discutível em alguns pontos (Bailey, 2017), o material representa de forma sucinta as intersecções entre as diversas áreas que compõe a Ciência de Dados.

Além da interdisciplinaridade inerente à Ciência de Dados, outro fator importante é a aplicabilidade de suas ferramentas às mais diversas áreas do conhecimento, como Gestão de Negócios, Saúde, Administração Pública, Engenharia e Robótica, Economia, Política, Agricultura e Pecuária, Jornalismo, Educação, entre outras. Por esta razão, a figura do Analista de Dados, profissional que detém o conhecimento das principais técnicas e ferramentas de Análise de Dados, é tão requisitada em praticamente todos os setores da sociedade.
No entanto, tanto para o Analista de Dados, quanto para qualquer outro profissional que trabalhe com Análise de Dados, é fundamental o domínio em dois pilares da Ciência de Dados: Estatística e Probabilidade.
Estatística e Probabilidade são duas áreas clássicas do conhecimento que, apesar de terem sido criadas em momentos distintos da história, apresentam um grande potencial sinérgico. A Estatística traduz-se como a ciência “que desenvolve e estuda métodos para coletar, analisar, interpretar e apresentar dados empíricos”, enquanto a Probabilidade configura-se como a “linguagem matemática utilizada para discutir eventos incertos” (UCI, 2020).
Conforme expresso na Figura 1.2, nestas etapas de coleta, análise, interpretação e apresentação de dados, a Estatística incorpora diversas ferramentas da Probabilidade. Na coleta, por exemplo, a Probabilidade pode ser útil no processo de amostragem dos dados. Definiremos alguns conceitos nas próximas seções, mas, de antemão, a Probabilidade nos ajuda a responder qual o tamanho amostral necessário para que determinado conjunto de dados possa representar, com alguma margem de erro, um comportamento observado em uma população. É o que acontece a cada dois anos com as pesquisas eleitorais. O número de entrevistas necessárias para se representar as intenções de voto da população é realizado pela Estatística através de métodos probabilísticos.
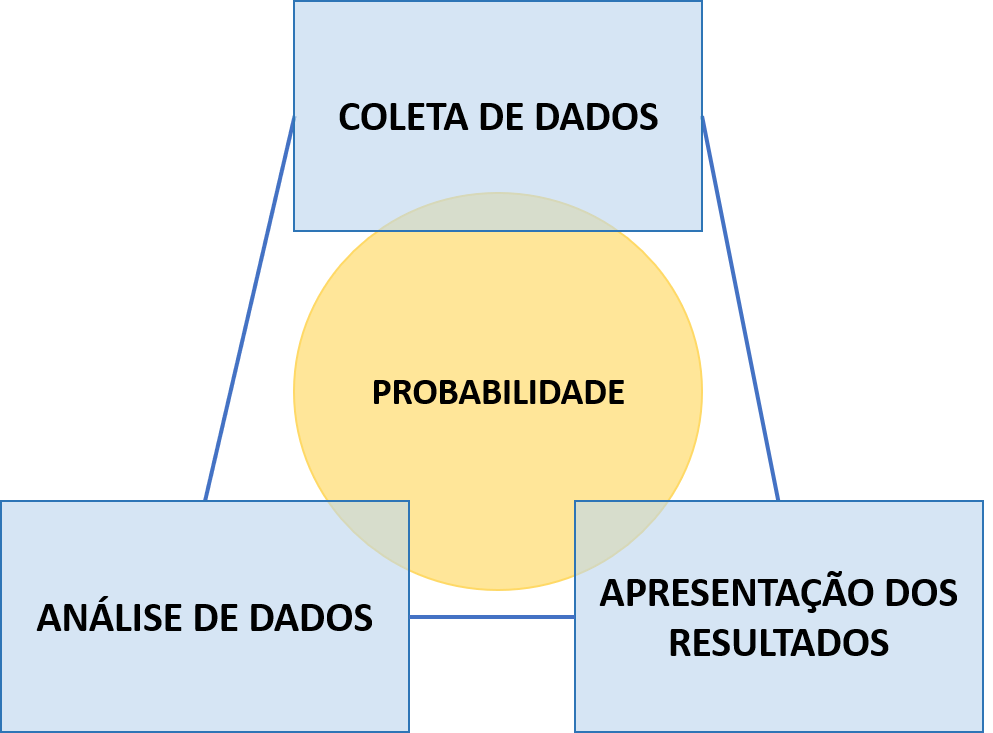
Nas etapas de análise, interpretação e apresentação, além de alguns modelos estatísticos incorporarem a Probabilidade em sua construção, como se observa na Estatística Bayesiana, geralmente os resultados são associados a uma margem de erro, que é um conceito probabilístico. Desta forma, observa-se que, de uma maneira ou de outra, que a Probabilidade e a Estatística, além de sinérgicas, são de difícil separação. Por estas razões, as duas áreas configuram-se como os principais pilares da Análise de Dados.
Para que se possa proceder com as análises de dados de modo mais eficiente, foram desenvolvidos, ao longo da história, diversos softwares computacionais. Um dos principais precursores deste processo foi a máquina tabuladora (Figura 1.3), criada ao final do século XIX por Herman Hollerith, inicialmente orientada para a tabulação de dados do censo americano. A máquina funcionava a partir da perfuração de cartões, tecnologia já inventada anteriormente, mas que foi incorporada na máquina de Hollerith. Por esta razão, ainda atualmente, diversos softwares utilizam a denominação cards para se referirem aos conjuntos de dados a serem analisados.

O sistema de perfuração de cartões foi utilizado por praticamente todo o século XX. Os primeiros compiladores das informações fornecidas pelos cartões foram criados na década de 1950 pela IBM, em uma linguagem padronizada denominada FORTRAN, ainda utilizada na atualidade. A partir da década de 1970, no entanto, os cartões foram gradualmente substituídos por comandos eletrônicos, já realizados nos próprios computadores, fator que favoreceu a diversidade de softwares e linguagens utilizados para fins de leitura, processamento e análise de dados.
Nos dias atuais, mesmo diante de um grande conjunto de possibilidades, é possível destacarmos algumas ferramentas principais, entre eles: Excel, SPSS, Biostat, Epidata, SAS, STATA, R e Python. Cada um deles foi criado ou para uma aplicação generalista, ou para uma finalidade específica, como análises nas áreas da Saúde, Agricultura e Economia. Além disso, todas estas ferramentas destacadas apresentam pontos positivos e negativos, mas que não serão tratados com profundidade neste livro.
Vale destacar, no entanto, que nos últimos anos tem sido observada uma onda de preferência por R e Python, ferramentas gratuitas muito utilizadas em análises estatísticas e algoritmos de Machine Learning. Neste livro, utilizaremos o R para a realização das atividades práticas propostas.
Assimile
O Machine Learning, também denominado Aprendizado de Máquina, é uma das áreas da Inteligência Artificial, com grande interface com a Análise de Dados. Com um complexo aparato matemático, estatístico e probabilístico em suas estruturas, os algoritmos de Machine Learning são orientados para o reconhecimento de padrões e comportamentos a partir de um determinado conjunto de dados. A filtragem anti-spam de e-mails, por exemplo, é realizada através de alguns algoritmos, que, a partir do reconhecimento de padrões, classifica os e-mails em spam ou não-spam. Os carros autônomos, os mecanismos de detecção de fraude, as inteligências para diagnósticos de doenças, as indicações de filmes, séries e músicas em plataformas de streaming... todos são exemplos de aplicação prática do Machine Learning. Há de se destacar, no entanto, que um bom analista de Machine Learning deve possuir uma base sólida de Estatística e Probabilidade.
O R é uma linguagem de programação criada em 1993 pelos pesquisadores Ross Ihaka e Robert Gentlemen, na Universidade de Auckland (Nova Zelândia). Segundo definição da própria R Foundation, o “R é um ambiente de software livre para computação estatística e gráficos”. Além disso, trata-se de uma ferramenta open source, ou seja, qualquer um pode utilizá-la e contribuir para a construção de seus pacotes. No formato padrão, a interface do software é bastante simples, conforme observado na Figura 1.4.

Uma das alternativas para o a interface padrão, inclusive recomendada para a realização das atividades deste livro, é o RStudio (Figura 1.5), um software também gratuito que integra o R em um ambiente dinâmico, permitindo análises e visualizações com maior rapidez e facilidade. O RStudio é formado por quatro quadros principais. Por padrão, no canto esquerdo superior está a Janela de Edição, em que são inseridos scritps de comandos executáveis. No canto esquerdo inferior, está o Console, que apresenta algumas informações básicas do software, registra os comandos executados na janela de edição e apresenta os resultados numéricos das análises realizadas. No canto direto superior, está a janela composta pelo Ambiente, Histórico e Conexões. O Ambiente registra os conjuntos de dados e as variáveis criadas dentro do contexto de análise. O Histórico apresenta uma quantidade limitada de códigos executados em um ou mais script. Por fim, a tela de Conexões traz a possibilidade de integração com ferramentas que operam com grandes bancos de dados. No canto direito inferior, estão as telas de Arquivos, Gráficos, Pacotes, Ajuda e Visualizador. Na tela de Arquivos, tem-se a possibilidade de abrir um script já salvo, visualizar um conjunto de dados ou abrir um documento externo ao R, como arquivo em planihas, bloco de notas, apresentações, entre outros. Na aba de Gráficos, são dispostos os resultados visuais das análises executas na janela de edição. Em Pacotes, tem-se a relação de todos os pacotes instalados e dos principais disponíveis no R. A tela de ajuda apresenta a possibilidade de se obter informações a respeito de algum comando ou pacote específico, enquanto o painel Visualizador permite obter resultados a partir de pacotes externos, como aqueles em formatos html ou integrados com alguma outra ferramenta.

O RStudio apresenta diversas ferramentas já integradas desde sua instalação, capazes de executar análises como sumarização de dados, operações matemáticas, análise de regressão, testes de hipóteses, gráficos, tabulações, entre outras. No entanto, é possível inserirmos novas funcionalidades, que nos permitirão utilizar uma série de recursos adicionais e potencializar nossas análises. Podemos, por exemplo, realizar um gráfico com melhor plasticidade e, até mesmo, uma análise mais específica, como um algoritmo de Machine Learning ou uma análise de série temporal. Para tanto, devemos realizar a instalação da biblioteca em que o nosso recurso de interesse foi disponibilizado. As bibliotecas, portanto, reúnem uma série de ferramentas adicionais, denominadas pacotes, que nos permitirão aprofundar os conhecimentos e adquirir algumas das competências que hoje são exigidas pelo mercado.
Há uma grande diversidade de pacotes disponíveis para utilização, muitos focados em um nicho de mercado/pesquisa específico. Podemos citar, por exemplo, o genetics, utilizado para uma série de análises específicas na área de genética, o ExpDes.pt, aplicado em delineamentos e análises de experimentos agrícolas e o quantmod, que possui uma inclinação para a área de finanças. Além destes casos específicos, temos algumas usabilidades um pouco mais generalizadas, das quais listamos as principais (GROLEMUND, 2021):
• ggplot2 (pacote): utilizado para gráficos customizáveis e com estética aprimorada, fator importante para a melhor visualização dos dados;
• tidyverse (biblioteca): conjunto de pacotes orientados para a manipulação de grandes dados, permitindo realizar operações desde a transformação, até a modelagem e apresentação dos resultados;
• dplyr (pacote): conjunto de ferramentas que permitem a manipulação por meio de filtragens, sumarizações, alterações, entre outras;
• lubridate (pacote): utilizado para a operação e manipulação de séries temporais;
• shiny (pacote): permite a realização de painéis e páginas interativas (aplicativos) por meio do R;
Não necessitamos decorar todas as bibliotecas e pacotes, afinal, estas são somente algumas das mais utilizadas. No entanto, é importante compreendermos suas principais usabilidades e como elas podem agregar em nosso dia a dia.
No exercício da análise de dados, iremos perceber que nem sempre teremos todas as respostas. Mas é de grande importância conhecermos os caminhos para encontrá-las. Por mais que o conteúdo abordado neste livro possa parecer complexo e extenso, trabalharemos juntos para desbravar a Estatística, a Probabilidade e o R! Partindo de conceitos iniciais, aprofundaremos os conteúdos aos poucos, trazendo contextualizações e exemplos de aplicação. Na próxima seção, exploraremos um pouco mais a Estatística, com algumas definições fundamentais para a Análise de Dados.
Faça valer a pena
Questão 1
A Probabilidade e Estatística são duas áreas distintas do conhecimento, mas frequentemente utilizadas em conjunto, explorando o potencial sinérgico que ambas possuem entre si. A Estatística é focada em questões de coleta, análise, interpretação e apresentação de dados, enquanto a Probabilidade aborda aspectos matemáticos aplicados à incerteza associada a determinados eventos.
A respeito da importância da Probabilidade e Estatística para a Análise de Dados, é correto dizer que:
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Correto!
Estatística e Probabilidade são duas áreas sinérgicas que, quando aplicadas em conjunto, oferecem um importante ferramental para a Análise de Dados. Por esta razão, não se pode dizer que uma ou outra não possui relevância para a Análise de Dados.
Questão 2
A Quarta Revolução Industrial inseriu a humanidade na Era da Informação, cujo elemento principal é o dado. Apesar de frequentemente confundidos, dado e informação são conceitos diferentes. Pode-se entender que os dados são os insumos principais daquilo que chamamos de informação.
A respeito dos conceitos de dado e informação, assinale a alternativa correta:
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Correto!
Dado e Informação são conceitos distintos, frequentemente confundidos. Dado traduz-se por todas as observações que coletamos e que apresentam geralmente em forma bruta. Por outro lado, a informação pode ser entendida como dados devidamente tratados e processados, orientados para uma relevância e propósito específico, ou seja, uma finalidade.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Questão 3
O software RStudio é uma interface utilizada para operações em linguagem R, que, por sua vez, é amplamente utilizado e difundido para diversas análises estatísticas e probabilísticas, considerando o bom desempenho e a vastidão de recursos que a linguagem apresenta. Veja, a seguir, a figura que apresenta a interface do RSudio:

A respeito da estrutura do software RStudio, assinale a alternativa correta:
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Correto!
O RStudio apresenta, de forma geral, quatro janelas principais. Cada uma dessas janelas apresenta uma ou mais telas de informação. Na Janela de Edição são inseridos os scritps de comandos executáveis. O Console apresenta informações básicas do software, registra os comandos executados na janela de edição e dispõe os resultados numéricos das análises. No Ambiente, são registrados os conjuntos de dados e as variáveis criadas dentro do contexto de análise. A tela de Conexões traz a possibilidade de integração com ferramentas que operam com grandes bancos de dados, enquanto o painel Visualizador permite obter resultados a partir de pacotes externos, como aqueles em formatos html ou integrados com alguma outra ferramenta. Nesse sentido, é correto afirmar que na Janela de Edição são inseridos os scripts de comandos.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Tente novamente...
Esta alternativa está incorreta, leia novamente a questão e reflita sobre o conteúdo para tentar outra vez.
Referências
BAILEY, B. A Modification of Drew Conway’s Data Science Venn Diagram. Towards Data Science, 3 abr. 2017. Disponível em: https://bit.ly/3gR9Cfj. Acesso em: 23 jan. 2021.
CHANG, W. et al. Shiny. R Package, 25 jan. 2020. Disponível em: https://bit.ly/35NEUxk. Acesso em: 23 jan. 2021.
CONWAY, D. The data science Venn diagram. Drew Conway Data Consulting, 30 set. 2010. Disponível em: https://bit.ly/35Jswyj. Acesso em: 29 dez. 2020.
DAVENPORT, T.; PRUSAK, L. Information ecology: Mastering the information and knowledge environment. Oxford University Press on Demand, 1997.
FERREIRA, E. B.; CAVALCANTI, P. P.; NOGUEIRA, D. A. ExpDes.pt. R Package, 14 dez. 2020. Disponível em: https://bit.ly/3gVJnD6. Acesso em: 23 jan. 2021.
GROLEMUND, G. Quick list of useful R packages. R Studio (Support) (comp.), 28 maio 2021. Disponível em: https://bit.ly/3xIbJaM. Acesso em: 23 jan. 2021.
HARARI, Y. N. Sapiens: uma breve história da humanidade. Porto Alegre: L&PM, 2015.
HOBSBAWM, E. A era das revoluções: 1789-1848. São Paulo: Paz e Terra, 2015.
HOBSBAWM, E. Era dos extremos: o breve século XX. Rio de Janeiro: Companhia das Letras, 1995.
RYAN, J. A. et al. Quantmod. R Package, 9 dez. 2020. Disponível em: https://bit.ly/3gNFLEg. Acesso em: 23 jan. 2021.
SEBRAE. DataSebrae. Disponível em: https://datasebrae.com.br/. Acesso em: 28 dez. 2020.
SPINU, V. et al. Lubridate. R Package, 26 fev. 2021. Disponível em: https://bit.ly/2TXYggx. Acesso em: 29 jan. 2021.
WARNES, G. et al. Genetics. R Package, 1 mar. 2021. Disponível em: https://bit.ly/3gXWG63. Acesso em: 23 jan. 2021.
WHAT is R? R Foundation, [s. d.]. Disponível em: https://bit.ly/2T1qyX7. Acesso em: 29 dez. 2020.
WHAT is Statistics? UCI, c2021. Disponível em: https://bit.ly/35MVzB6. Acesso em: 29 dez. 2020.
WICKHAM, H. et al. ggplot2. R Package, 30 dez. 2020. Disponível em: https://bit.ly/3d8qyvl. Acesso em: 23 jan. 2021.
WICKHAM, H. et al. Welcome to the Tidyverse. Journal of Open Source Software, v. 4, n. 43, p. 1686, 2019. Disponível em: https://bit.ly/2UzsarP. Acesso em: 23 jan. 2021.
WICKHAM, Hadley et al. dplyr. 2021. R Package. Disponível em: https://bit.ly/3xQ0ayp. Acesso em: 23 jan. 2021.